NodeTask
Defines a node classification or regression GNN learning task.
Parameters
Section titled “Parameters”| Name | Type | Description | Optional |
|---|---|---|---|
connector | SnowflakeConnector | The connector object used for sending requests to the GNN engine. | No |
name | str | The name of the task, can be anything describing the task at hand. The name must comply with Snowflake object identifier rules. | No |
task_data_source | Dict | A dictionary mapping split names to table paths. For training, "train" and "validation" keys are required, while "test" is optional. For inference-only workflows, only "test" is required. Each value is a fully qualified Snowflake table name in Database.Schema.Table format. Multiple splits may reference the same table. | No |
label_column | str | The name of the column in the train and validation and (optionally) test tables containing the labels. The label column is the column holding the values that will be used to train the model. (Users can choose not to provide labels for the test data.) | No |
target_entity_column | ForeignKey | A foreign key that specifies the name of the target entity column in the training, validation, and test tables, and references the corresponding target entity GNNTable and its column. The column identified by this foreign key represents the target nodes in the task for which the model will make predictions. The node IDs contained in the foreign key’s column_name must match, or be a subset of, the values in the column specified by the foreign key’s link_to attribute. | No |
task_type | TaskType | The type of the node task, it can be one of TaskType.BINARY_CLASSIFICATION, TaskType.MULTICLASS_CLASSIFICATION, TaskType.MULTILABEL_CLASSIFICATION or TaskType.REGRESSION | No |
time_column | str | If the dataset includes a time-based dimension, you can specify a timestamp column to incorporate temporal dependencies. Only one time column is supported. For details, see the Time Columns section. | Yes |
evaluation_metric | EvaluationMetric | The name of the evaluation metric that we want to optimize for | Yes |
current_time | bool | If set to False the current time of the task table will be reduced by one time unit. Useful when the time column at the task table does not need to see the values from the database tables at the same timestamp | Yes |
Examples
Section titled “Examples”Binary Classification Task With Time
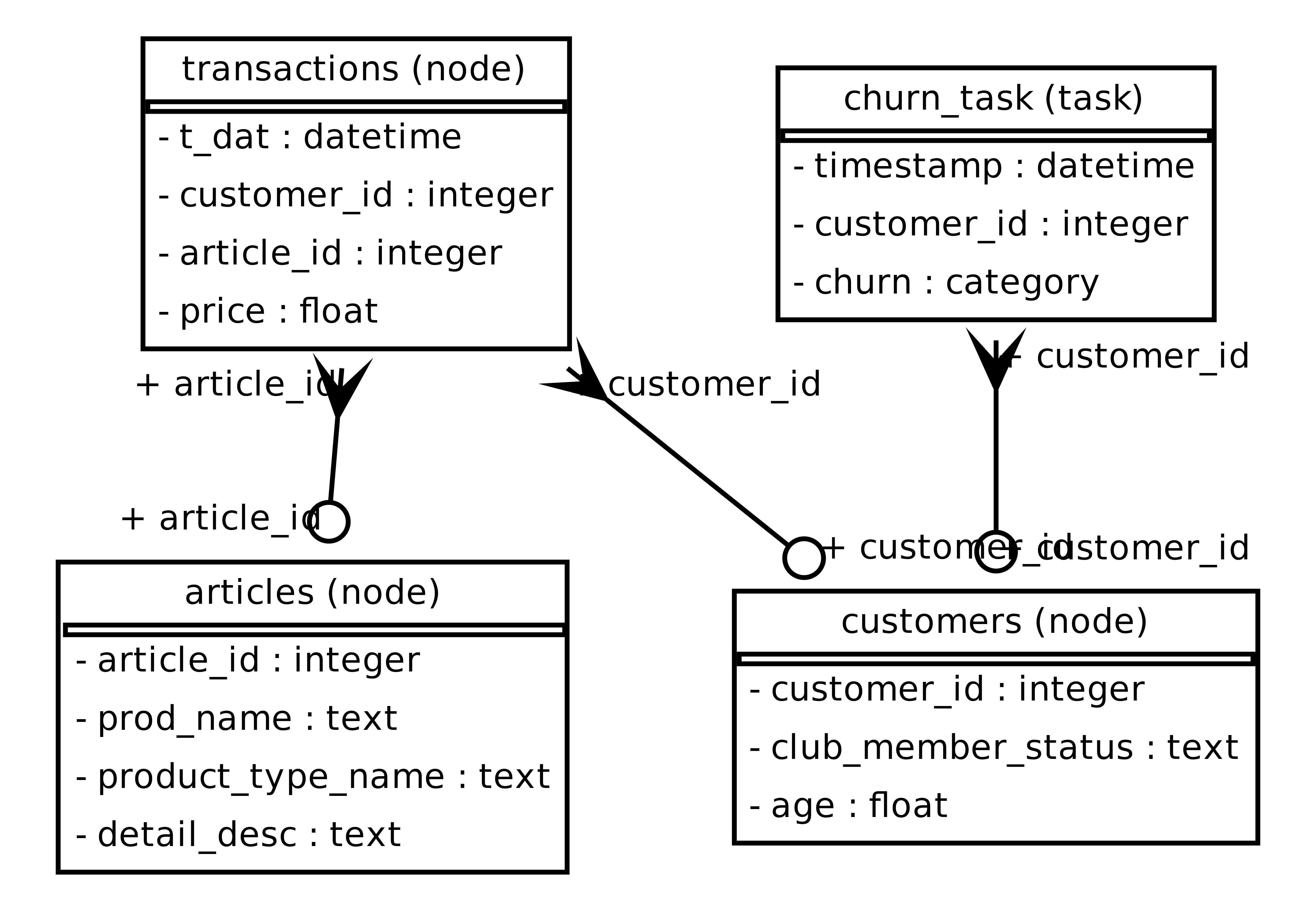
Section titled “Binary Classification Task With Time”As shown in the figure, this dataset contains three tables:
customerswith candidate keycustomer_idarticles(products) with candidate keyarticle_idtransactionswith two foreign keys:customer_idlinking to thecustomerstable, andarticle_idlinking to thearticlestable, as well as a time columnt_dat.
Each row in the transactions table shows that a specific customer (customer_id) buying a specific product (article_id) on a specific date (t_dat).
Our task (churn_task) is a node-level binary classification task (binary_classification): given a customer and a date, we want to predict whether they are likely to churn in the next month. The time column is required so that the model does not see future transactions when making predictions.
In this example, the node of interest is the customers table, since we are predicting churn for customers. Therefore, the target_entity_column links to the customers table.
In this case, the task can be defined as follows:
from relationalai_gnns import NodeTask, TaskType, ForeignKey
# The task_data_source maps each dataset split to the corresponding table name.
binary_clf_task = NodeTask( connector=connector, name="churn_task", task_data_source={ "train": "DATABASE.SCHEMA.TRAIN", "test": "DATABASE.SCHEMA.TEST", "validation": "DATABASE.SCHEMA.VALIDATION" }, target_entity_column=ForeignKey(column_name="id", link_to="TableWithCKey.Id"), time_column="timestamp", label_column="label", task_type=TaskType.BINARY_CLASSIFICATION)Regression Task and Evaluation Metric Setup
Section titled “Regression Task and Evaluation Metric Setup”from relationalai_gnns import NodeTask, TaskType, ForeignKeyfrom relationalai_gnns import EvaluationMetric
regr_task = NodeTask( connector=connector, name="my_node_task", task_data_source={ "train": "DATABASE.REGRESSION_SCHEMA.TRAIN", "test": "DATABASE.REGRESSION_SCHEMA.TEST", "validation": "DATABASE.REGRESSION_SCHEMA.VALIDATION" }, target_entity_column=ForeignKey(column_name="target_id", link_to="TableWithCKey.Id"), label_column="value", task_type=TaskType.REGRESSION, evaluation_metric=EvaluationMetric(name="r2"))Inference-Only Task
Section titled “Inference-Only Task”If you only need to run inference (no training), you can create a task with just a "test" split:
from relationalai_gnns import NodeTask, TaskType, ForeignKey
inference_task = NodeTask( connector=connector, name="my_inference_task", task_data_source={ "test": "DATABASE.SCHEMA.TEST" }, target_entity_column=ForeignKey( column_name="id", link_to="TableWithCKey.Id" ), task_type=TaskType.BINARY_CLASSIFICATION)Inference-only tasks can be used with trainer.predict() (by passing the task inside a new Dataset) but cannot be passed to trainer.fit() or trainer.fit_predict().
Methods
Section titled “Methods”NodeTask inherits from the GNNTable, so it has the same methods. It additionally provides a show_task() method:
.show_task()
Section titled “.show_task()”Prints the task metadata schema and task details.
Example
Section titled “Example”binary_clf_task.show_task()Attributes
Section titled “Attributes”.label_column
Section titled “.label_column”Retrieves label_column. Cannot be set after initialization. It is read-only.
.target_entity_column
Section titled “.target_entity_column”Retrieves target_entity_column. Cannot be set after initialization. It is read-only.
.current_time
Section titled “.current_time”Retrieves current_time. Cannot be set after initialization. It is read-only.